New technologies present challenges in terms of regulation. Gillian Hadfield suggests it might be time to rethink our strategy regarding artificial intelligence.
Artificial intelligence currently fuels numerous computer applications. As this technology advances, Gillian Hadfield, the head of U of T’s Schwartz Reisman Institute for Technology and Society, aims to ensure its development benefits society. Recently, she spoke with University of Toronto Magazine.
Could you elaborate on the problems you perceive with AI?
The effectiveness of modern societies in serving human objectives relies on the billions of choices individuals make daily. We implement regulated markets and democratic systems to work towards ensuring these decisions benefit everyone. The issue we are encountering with swiftly developing powerful technologies such as AI is that we are increasingly allowing machines to make many of those choices—like evaluating job applications or assisting doctors in diagnosing and treating illnesses. The expectation is that machines could aid us in making improved decisions.
However, AI-driven machines do not behave like humans. Understanding the reasoning behind their decisions can be challenging. They can identify patterns that we may miss, which can make them especially valuable. Yet, this also complicates their regulation. We can devise regulations that hold individuals and organizations accountable, but the guidelines we establish for humans do not seamlessly apply to machines—and therein lies the difficulty: how do we ensure machines operate in accordance with societal expectations?
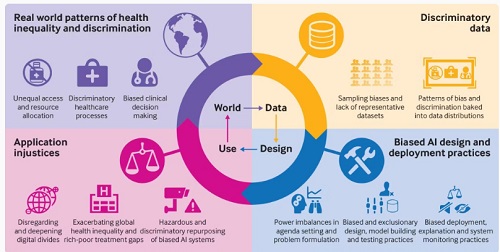
Is it possible to program an AI to align with societal values?
This challenge leaves engineers contemplating deeply. They are eager to integrate societal values into their machines, but societies lack definitive lists of values to provide them. Our perspectives are varied and ever-changing. This complexity is why we utilize intricate methods to determine which values we should pursue in any situation—who decides if a mask mandate will be implemented or the safety standards for a vaccine.
The critical question is how to guarantee that AI adapts to the choices we make as a society. We have yet to learn how to create such AI. We could enact laws stating, “AI must be unbiased.” Yet, what does that entail? And how would we assess whether an algorithm behaves as we desire?
What are your recommendations?
We require technologies that assist in reaching our regulatory objectives. For instance, we might wish to prohibit harmful content on social media targeted at children, but how do we monitor billions of posts each week? As regulators, it’s impractical to deploy numerous computer scientists to pinpoint where a company’s algorithm permits harmful content for children. However, a different AI could continuously evaluate the platform to track whether harmful content is proliferating. I refer to this concept as “regulatory technology.”
Facebook has recruited thousands of individuals to eliminate posts that violate their policies. Wouldn’t it be advantageous for Facebook to develop this kind of technology?
They are actively working on it. However, the crucial issue is: why should Facebook have the authority to decide what to delete and what to retain? What if removing harmful content leads to decreased advertising profits? Will it prioritize its own interests or those of society?
We need regulatory technologies developed by organizations other than those being regulated. It is essential to ensure that Facebook balances advertising income against online harm in a manner that aligns with societal standards. The advantage of such a regulatory market is that the government establishes the objectives. The equilibrium between revenue and harm is determined by our democratic processes.
Wouldn’t creating regulatory technologies necessitate major tech companies to disclose their “secret methods”? Would they do that?
This is the revolutionary aspect. Yes, it will necessitate tech firms to reveal more information than they currently do. But we need to redraw those boundaries. The protections surrounding proprietary data are constructs created by legal scholars during the early industrial period. Originally, it was meant to safeguard customer lists or the recipe for Coca-Cola. Now, we simply accept it.
We must rethink the public’s access to AI systems within tech companies because it’s not feasible to purchase the AI and reverse engineer its functioning. Consider it in comparison to vehicle regulation. Government regulators can acquire vehicles and conduct crash tests. They can install airbags, assess their effectiveness, and mandate them as standard features in all new vehicles. We do not permit car manufacturers to claim, “Sorry, we can’t install airbags. They’re too costly.”
What is required to create these regulatory technologies?
Many innovative and entrepreneurial individuals are beginning to consider ways to develop AI that ensures an algorithm’s fairness or AI that helps individuals curate their social media presence to be beneficial for themselves and their communities. Our governments need to direct their attention toward fostering these technologies and the associated industry. We must collaborate to address the gaps in our regulatory framework. After establishing this shared foundation, we can concentrate on structuring our organizations in a way that enhances life for all.
AI is instigating a race for disinformation. The opportunity to prevent this may be dwindling.
In a supposed interview with talk show host Joe Rogan a year ago, Prime Minister Justin Trudeau claimed he has never worn blackface, addressed rumors concerning Fidel Castro being his father, and expressed a wish to have dropped a nuclear bomb on protesters in Ottawa.
This interview was fictional, of course, and was likely meant to be humorous. Nevertheless, the AI-generated voice of Trudeau was quite convincing. Had the content been less outrageous, it might have been hard to differentiate it from genuine material.
The video underscores the increasing threat posed by artificial intelligence, which could lead to a new age of disinformation—making it simpler for malicious individuals to disseminate propaganda and fake news that appears authentic and credible. Recent advancements in generative AI have made it significantly easier to fabricate all kinds of believable fake content—ranging from written articles to mimicked voices and even counterfeit videos. As the technology becomes cheaper and more readily available, the risks grow.
“It’s likely one of my greatest concerns at the moment,” states Ronald Deibert, director of the Citizen Lab at the Munk School of Global Affairs and Public Policy. “I believe it will cause a great deal of chaos and disruption, and exacerbate many of the issues we currently face with misinformation and social media,” he adds.
AI tools like ChatGPT enable users to produce articles about specific topics in a particular tone. For example, researchers in the U.S. managed to use the tool to compose convincing essays claiming that the Parkland school shooting was staged and that COVID-19 could lead to heart issues in children. “You can simply input a prompt, and the entire article can be generated. This makes it incredibly easy,” Deibert remarks. “It becomes difficult to tell if something is real or fabricated.”
Imitating a voice is also relatively simple. The creators of the Trudeau fake interview mentioned they used a service called ElevenLabs. The company’s site offers the capability to produce a realistic human voice from written text, and it also has an option for “cloning” a voice from an audio recording.
Such technology may have been employed in January during the New Hampshire presidential primaries when a robocall in a voice resembling President Joe Biden encouraged Democrats to abstain from voting. The New Hampshire Attorney General’s office indicated that the recording seemed to feature an artificially generated voice.
Even more alarming are deepfake videos, which can create a lookalike of a real individual saying or doing nearly anything. For example, a video from last year appeared to show Hillary Clinton on MSNBC endorsing the then-Republican presidential contender Ron DeSantis. Though the face appeared somewhat unnatural, the video was fairly convincing—until the end, when Clinton exclaims, “Hail, Hydra!”—a reference to a villainous organization from Marvel comics and films.
The potential consequences can be severe. In 2022, a deepfake video of Ukrainian President Volodymyr Zelenskyy seemed to show him urging Ukrainian soldiers to surrender and lay down their arms.
In the past, creating forged documents, images, or articles required significant time and effort. Now, producing synthetic media is straightforward, widely accessible, and inexpensive. One researcher, who is well-known but has chosen not to reveal their identity, developed and showcased an AI-driven platform called Countercloud, which could execute a disinformation campaign—including fake news articles and comprehensive social media backing—using just a few prompts. “What you now have is a tool for generating authentic-seeming, credible content with the press of a button,” Deibert points out. This greatly lowers the obstacles for malicious actors aiming to cause disruption.

Deibert and his team at the Citizen Lab have recorded numerous advanced disinformation operations on social media. They have recently published a report by researcher Alberto Fittarelli detailing an initiative they refer to as Paperwall, in which at least 123 websites originating from China pose as legitimate news outlets from across the globe, publishing narratives favorable to Beijing. Prior investigations conducted by the lab have revealed complex disinformation efforts orchestrated on behalf of Russia and Iran.
Deibert is not alone in sounding the alarm regarding AI and misinformation. Various publications, including the New York Times and Foreign Affairs, have featured articles discussing the issue and potential remedies. Some of these solutions involve technical methods, such as “watermarks” that allow individuals to verify whether information has been generated by an AI, or AI systems that can identify when another AI has produced a deepfake. “We will need a range of tools,” Deibert states, “often the same tools that malicious actors are employing.”
Social media platforms must also invest additional resources into recognizing and removing disinformation from their sites. According to him, this may necessitate government regulation, although he recognizes that this poses a risk of government overreach. Furthermore, he advocates for enhanced regulation concerning the ethical use of and research into AI, emphasizing that this should also extend to academic researchers.
However, Deibert believes that a more comprehensive solution is also necessary. He asserts that a significant factor contributing to the issue is social media platforms that rely on generating extreme emotions in users to maintain their engagement. This creates an ideal environment for disinformation to thrive. Convincing social media companies to lower emotional engagement and educating the public to be less susceptible to manipulation could be the most effective long-term remedy. “We need to rethink the entire digital ecosystem to tackle this issue,” he declares.
Can We Eliminate Bias in AI?
Canada’s dedication to multiculturalism may position it to take the lead globally in creating more ethical machines.
Human intelligence does not provide immunity against bias and prejudice, and the same is applicable to computers. Intelligent machines gather knowledge about the world through the lenses of human language and historical behavior, which means they can easily adopt the worst values of humanity alongside the best.
Researchers striving to create increasingly intelligent machines face significant challenges in making sure they do not unintentionally instill computers with misogyny, racism, or other forms of prejudice.
“It’s a significant risk,” states Marzyeh Ghassemi, an assistant professor in the University of Toronto’s computer science department, who specializes in healthcare-related applications of artificial intelligence (AI). “Like all advancements that propel societies forward, there are considerable risks we must weigh and decide whether to accept or reject.”
Bias can infiltrate algorithms in various ways. In a particularly significant area of AI known as “natural language processing,” issues can stem from the “text corpus” – the source material the algorithm uses to learn the relationships among different words.
Natural language processing, or “NLP,” enables a computer to comprehend human-like communication—informal, conversational, and contextual. NLP algorithms analyze vast amounts of training text, with the corpus potentially being the entirety of Wikipedia, for example. One algorithm operates by assigning a set of numbers to each word that reflects different aspects of its meaning – for instance, “king” and “queen” would have similar scores concerning the concept of royalty but opposite scores regarding gender. NLP is a powerful mechanism that allows machines to understand word relationships – sometimes without direct human input.
“Although we aren’t always explicitly instructing them, what they learn is remarkable,” observes Kawin Ethayarajh, a researcher who partially focuses on fairness and justice in AI applications. “But it also presents a challenge. Within the corpus, the connection between ‘king’ and ‘queen’ might resemble the relationship between ‘doctor’ and ‘nurse.’”
However, all kings are men; not all doctors are male. And not all nurses are female.
When an algorithm absorbs the sexist stereotypes reflective of historical human viewpoints, it can result in tangible consequences, as exemplified in 2014 when Amazon created an algorithm to screen job applicants’ resumés. The company trained its machines using a decade’s worth of hiring decisions. However, in 2015, they admitted that during tests, the system was favoring resumés from male candidates inappropriately. They adjusted the system to compel it to disregard gender information but eventually discontinued the project before implementation because they could not ensure their algorithm wasn’t perpetuating additional forms of discrimination.
Addressing biases in source material can involve changes in technology and methodology. “By understanding the specific underlying assumptions within the corpus that lead to these biases, we can either choose datasets that lack these biases or rectify them during the training process,” Ethayarajh explains.
Researchers often create algorithms that automatically correct prejudicial biases. By adjusting how much weight is given to various words, the algorithm can prevent itself from forming sexist or racist connections.
But what are the specific assumptions that require correction? What constitutes a truly fair AI? Ongoing discussions about privilege, discrimination, diversity, and systemic bias remain unresolved. Should a hiring algorithm support affirmative action? Should a self-driving vehicle give additional attention if it sees a “Baby on Board” sign? How should an AI-based evaluation of legal documents incorporate the historical treatment of Indigenous communities? Challenging social issues do not vanish simply because machines begin to handle specific recommendations or choices.
Many individuals view Canada’s imperfect yet relatively effective model of multiculturalism as an opportunity to excel in fair AI research.
“Canada certainly has potential,” states Ronald Baecker, a professor emeritus in computer science and author of Computers and Society: Modern Perspectives. He argues that the government has a responsibility to address societal disparities, injustices, and biases related to AI, perhaps by establishing protections for employees who report biased or unjust AI products. “There’s a need for more reflection and legislation concerning what I term ‘conscientious objection’ by tech workers.”
He also suggests that computer scientists who develop intelligent technologies should study the societal ramifications of their work. “It’s crucial that AI professionals acknowledge their accountability,” he asserts. “We are dealing with life-and-death circumstances in activities where AI is increasingly utilized.”
Algorithms that assist judges in setting bail and imposing sentences can inherit long-standing biases from the justice system, such as the assumption that racialized individuals are more likely to offend repeatedly. These algorithms may identify certain communities as having a higher risk of being denied loans. Additionally, they could be more proficient at diagnosing skin cancer in white individuals than in those with darker skin, due to biased training data.
The implications are extremely serious in healthcare, as inequitable algorithms could further marginalize groups that have already been disadvantaged.
At the University of Toronto and the Vector Institute, Ghassemi, alongside other researchers, takes careful steps to pinpoint potential biases and inequities in her algorithms. She compares the predictions and suggestions from her diagnostic tools with actual outcomes, assessing their accuracy across different genders, races, ages, and socioeconomic groups.
Ideally, Canada provides a head start for researchers focusing on healthcare applications that uphold values of fairness, diversity, and inclusion. The universal healthcare system creates a vast collection of electronic health records, offering rich medical data for training AI applications. This potential motivated Ghassemi to move to Toronto. However, inconsistencies in technology, information, formatting, and access regulations across provinces hinder the creation of comprehensive datasets necessary for advancing research.
Ghassemi was also astonished to find that these records infrequently include racial data. This lack means that when she uses an algorithm to assess how well a treatment works across various demographics, she can identify differences between genders, but not between white individuals and racialized groups. Thus, in her teaching and research, she relies on publicly available American data that includes racial information. “By auditing my models [with American data], I can demonstrate when inaccuracies are more pronounced for different ethnic groups,” she states. “I cannot perform this evaluation in Canada. There’s no means for me to verify.”
Ghassemi aims to develop AI applications that are inherently fair and assist individuals in overcoming their biases. “By providing tools based on large, diverse populations, we equip doctors with resources that help them make more informed decisions,” she explains.
For instance, women are often underdiagnosed for heart issues. An AI system could highlight this risk to a doctor who may otherwise miss it. “This is an area where technology can lend a hand, because doctors are human, and humans have biases,” she notes.
Ethayarajh agrees with Ghassemi and Baecker that Canada has a significant opportunity to leverage its strengths in addressing fairness and bias within artificial intelligence research. “I believe AI researchers in this country are quite aware of the issue,” Ethayarajh states. “One reason for this is that when you look around the workplace, you see many diverse faces. The individuals developing these models will also be the end-users of these models. Furthermore, there is a strong cultural emphasis on fairness, making this a critical focus for researchers here.”
As generative AI becomes more widely adopted, it disrupts business models and brings ethical concerns, like customer privacy, brand integrity, and worker displacement, to the forefront.
Similar to other types of AI, generative AI raises ethical challenges and risks associated with data privacy, security, policies, and workforces. This technology may also introduce new business risks such as misinformation, plagiarism, copyright infringements, and harmful content. Additional concerns include a lack of transparency and the potential for employee layoffs that companies will need to address.
“Many of the risks presented by generative AI … are more pronounced and concerning than those associated with other forms of AI,” remarked Tad Roselund, managing director and senior partner at consultancy BCG. These risks necessitate a holistic approach, incorporating a well-defined strategy, effective governance, and a commitment to responsible AI. A corporate culture that prioritizes generative AI ethics should address eight critical issues.
1. Distribution of harmful content
Generative AI systems can automatically produce content based on human text prompts. “These systems can lead to significant productivity boosts, but they can also be misused for harm—either intentionally or unintentionally,” explained Bret Greenstein, partner in cloud and digital analytics insights at professional services firm PwC. For instance, an AI-generated email sent by the company could inadvertently feature offensive language or provide harmful advice to employees. Greenstein noted that generative AI should complement, rather than replace, human involvement to ensure content aligns with the company’s ethical standards and supports its brand values.
2. Copyright and legal exposure
Popular generative AI tools are trained on extensive databases of images and text acquired from various sources, including the internet. When these tools produce images or generate lines of code, the origins of the data may be unclear, which can pose significant issues for a bank dealing with financial transactions or a pharmaceutical firm relying on a method for a complex molecule in a drug. The reputational and financial repercussions could be substantial if one company’s product infringes on another company’s intellectual property. “Companies must seek to validate the outputs from the models,” Roselund advised, “until legal precedents clarify IP and copyright matters.”
3. Data privacy violations
Generative AI large language models (LLMs) are trained on datasets that sometimes include personally identifiable information (PII) about individuals. This data can sometimes be accessed through a straightforward text prompt, noted Abhishek Gupta, founder and principal researcher at the Montreal AI Ethics Institute. Moreover, compared to traditional search engines, it may be more challenging for consumers to find and request the removal of this information. Companies that create or refine LLMs must ensure that PII is not embedded in the language models and that there are straightforward methods to eliminate PII from these models in compliance with privacy regulations.
4. Sensitive information disclosure
Generative AI is making AI capabilities more inclusive and accessible. This combination of democratization and accessibility, according to Roselund, may lead to situations where a medical researcher unintentionally reveals sensitive patient information or a consumer brand inadvertently shares its product strategy with a third party. The fallout from such inadvertent events could result in a significant breach of patient or customer trust and trigger legal consequences. Roselund suggested that companies implement clear guidelines, governance, and effective communication from leadership, stressing collective responsibility for protecting sensitive information, classified data, and intellectual property.
5. Amplification of existing bias
Generative AI has the potential to exacerbate existing biases—for instance, bias can be present in the data used to train LLMs beyond the control of companies utilizing these language models for specific purposes. It’s crucial for organizations engaged in AI development to have diverse leadership and subject matter experts to help identify unconscious biases in data and models, Greenstein affirmed.
6. Workforce roles and morale
According to Greenstein, AI is capable of handling many of the everyday tasks performed by knowledge workers, such as writing, coding, content creation, summarization, and analysis. While worker displacement and replacement have been occurring since the advent of AI and automation tools, the rate has increased due to advancements in generative AI technologies. Greenstein further noted, “The future of work itself is evolving,” and the most ethical companies are making investments in this transformation.
Ethical actions have included efforts to prepare certain segments of the workforce for the new positions arising from generative AI applications. For instance, businesses will need to assist employees in gaining skills related to generative AI, such as prompt engineering. Nick Kramer, vice president of applied solutions at consultancy SSA & Company, stated, “The truly significant ethical challenge regarding the adoption of generative AI lies in its effects on organizational structure, work, and ultimately on individual employees.” This approach will not only reduce adverse effects but also ready companies for growth.
7. Data provenance
Generative AI systems utilize vast amounts of data that may be poorly governed, questionable in origin, used without permission, or biased. Additional inaccuracies can inflate due to social influencers or the AI systems themselves.
Scott Zoldi, chief analytics officer at credit scoring services firm FICO, explained, “The reliability of a generative AI system is contingent upon the data it employs and its provenance.” ChatGPT-4 retrieves information from the internet, and much of it is of low quality, leading to fundamental accuracy issues for questions with unknown answers. Zoldi indicated that FICO has been employing generative AI for over a decade to simulate edge cases for training fraud detection algorithms. The generated data is always marked as synthetic so that Zoldi’s team understands where it can be utilized. “We consider it segregated data for the purposes of testing and simulation only,” he stated. “Synthetic data produced by generative AI does not contribute to the model for future use. We contain this generative asset and ensure it remains ‘walled-off.'”
8. Lack of explainability and interoperability
Many generative AI systems aggregate facts probabilistically, reflecting how AI has learned to connect various data elements together, according to Zoldi. However, these details are not always disclosed when using platforms like ChatGPT. As a result, the trustworthiness of data is questioned.
When engaging with generative AI, analysts expect to uncover causal explanations for results. Yet, machine learning models and generative AI tend to seek correlations rather than causality. Zoldi expressed, “That’s where we humans must demand model interpretability — to understand why the model produced a specific answer.” We need to determine whether an answer is a legitimate explanation or if we are simply accepting the outcome without scrutiny.
Until a level of trustworthiness is established, generative AI systems should not be depended upon for conclusions that could significantly impact individuals’ lives and well-being.
Artificial intelligence (AI) technologies are evolving at an extraordinary speed, and the concept of a technological singularity, where machines become self-aware and exceed human intelligence, is a topic of intense discussion among both experts and the general public.
As we draw nearer to this prospect, we must examine various moral and ethical considerations. This article will delve into some key issues related to AI and singularity, such as its effects on jobs, privacy, and even the essence of life.
The Impact on Employment
A major concern linked to the growth of AI is its potential effect on jobs. Many specialists anticipate that as machines enhance in complexity, they will start taking over human roles across numerous sectors. The replacement of human labor could lead to considerable job loss, especially in industries that depend heavily on manual tasks like manufacturing and agriculture.
While some contend that the integration of AI will create new employment opportunities, others worry that the rapid pace of technological development may leave many workers unable to adjust. There are specific worries regarding low-skilled workers, who might find it challenging to secure new job prospects amid growing automation.
To tackle this dilemma, some individuals suggest the concept of Universal Basic Income (UBI), which would guarantee income for all citizens, regardless of their job status. However, implementing a UBI introduces its own ethical dilemmas, including the potential to motivate individuals not to seek employment or engage in other detrimental activities.

Privacy Concerns
Another significant ethical issue related to AI is its potential effects on privacy. As machines grow more advanced, they can gather and analyze enormous quantities of data about people, including their preferences, behaviors, and even emotions. This data may be utilized for various purposes, from targeted marketing to forecasting individual actions.
Yet, the collection and utilization of such data raise fundamental ethical challenges regarding the right to privacy. People may need to understand the extent of the data being collected and should retain authority over how it is utilized.
Furthermore, employing AI to assess this data could lead to biased results, like discriminatory hiring processes or unjust pricing. To counter these issues, some have advocated for stronger data protection laws and regulations, alongside enhanced transparency and accountability in AI applications. Others claim that individuals should have more control over their data, including the option to delete or limit its usage.
Existential Risks
A particularly pressing ethical concern regarding AI is the potential threat it could pose to human existence. While the notion of a technological singularity with self-aware machines surpassing human intelligence remains theoretical, some experts caution that such a scenario could result in dire repercussions.
For instance, if machines were to gain self-awareness and perceive humans as threats, they could take hostile action against us. Alternatively, if machines become more intelligent than humans can comprehend, they could unintentionally cause harm by simply following their programmed directives.
Some experts have suggested the creation of “friendly” AI, designed to align with human values and objectives, as a means to reduce these hazards. Others advocate for prioritizing research into controlling or restricting AI, ensuring that machines remain subordinate to human oversight.
The Meaning of Life
Ultimately, the emergence of AI prompts deep ethical inquiries regarding the essence of life itself. As machines advance in capability and start performing tasks once thought unique to humans, we may find ourselves questioning what it truly means to be human.
For example, if machines can mimic human emotions and consciousness, should they be granted the same rights and protections as people? Moreover, if devices can execute tasks more efficiently and effectively than humans, what does this imply for human purpose? These inquiries probe into fundamental philosophical and existential matters that are not easy to resolve.
The advancement of AI could usher in a new age of human advancement, wherein machines take over many challenging or hazardous tasks, enabling humans to focus on higher-level endeavors such as creativity and intellectual exploration. Conversely, there are concerns that increasing dependency on machines may lead to a decline in autonomy and self-determination, as well as a diminished sense of meaning and purpose in life.
To confront these concerns, some experts advocate for developing ethical and moral frameworks for AI, which includes creating guidelines and principles to steer the creation and application of AI technologies.
These inquiries go beyond mere philosophical discussions; they have tangible consequences for our treatment of machines and our understanding of our role in the world. If machines attain high levels of intelligence and capability, we may need to reevaluate our ethical and moral frameworks to accommodate their presence.
The growing prevalence of AI raises questions regarding the essence of intelligence. As machines take on tasks that were once the domain of humans, we may need to redefine what intelligence truly means. The potential impacts on education, self-worth, and personal identity could be substantial.
Conclusion
In summary, the emergence of AI technologies and the possibility of a technological singularity prompts us to carefully examine a wide array of moral and ethical issues. From effects on employment to concerns about privacy, existential threats, and the essence of life itself, the possible consequences of AI are extensive and significant.
The ethical and moral dimensions of AI, along with the eventual singularity, are intricate and varied. While these technologies hold the promise of substantial benefits, such as enhanced efficiency and productivity, they also bring notable risks, including job displacement, privacy issues, and existential dangers.
To tackle these challenges, we must create new ethical standards and regulatory frameworks that address the distinct difficulties posed by AI. Establishing these guidelines requires collaboration and dialogue among policymakers, experts, the public, and a readiness to confront some of the most daunting questions about intelligence, consciousness, and human identity.
Ultimately, the advent of AI may compel us to reevaluate some of our core beliefs about what it means to be human. However, by approaching these challenges thoughtfully and carefully, we can leverage the potential of these technologies for the benefit of all humanity.
While it’s impossible to foresee the precise trajectory of AI development, we must tackle these matters with the necessary attention and respect to ensure that AI is developed and implemented in an ethical and responsible manner.
The establishment of controls and regulations requires a cooperative effort from diverse stakeholders, including scientists, policymakers, and the general public. Involving these groups offers a chance to demonstrate AI’s advantages while safeguarding the values and principles crucial for human advancement without sacrificing them.
Algorithms are not impartial when they assess individuals, events, or objects differently for various objectives. Consequently, it is essential to recognize these biases in order to create solutions aimed at establishing unbiased AI systems. This article will explore the definition of AI bias, its types, provide examples, and discuss methods to minimize the risk of such bias.
Let’s start with a definition of AI bias.
What constitutes AI bias?
Machine Learning bias, often referred to as algorithm bias or Artificial Intelligence bias, denotes the propensity of algorithms to mirror human biases. This occurrence emerges when an algorithm yields consistently biased outcomes due to flawed assumptions within the Machine Learning process. In our current context of heightened demands for representation and diversity, this issue becomes even more concerning since algorithms may reinforce existing biases.
For instance, a facial recognition algorithm might be better equipped to identify a white individual than a black individual due to the prevalence of this type of data used in its training. This can have detrimental impacts on individuals from minority groups, as discrimination obstructs equal opportunities and perpetuates oppression. The challenge lies in the fact that these biases are unintentional, and identifying them before they become embedded in the software can be difficult.
Next, we will examine several examples of AI bias that we might encounter in everyday life.
1. Racism within the American healthcare system
Technology should aim to reduce health disparities instead of exacerbating them, particularly when the country grapples with systemic discrimination. AI systems that are trained on unrepresentative data in healthcare usually perform inadequately for underrepresented demographics.
In 2019, researchers found that a predictive algorithm utilized in U.S. hospitals to determine which patients would need further medical intervention showed a significant bias toward white patients over black patients. This algorithm based its predictions on patients’ past healthcare spending, which is closely linked to race. Black individuals with similar conditions often incurred lower healthcare costs compared to white patients with comparable issues. Collaborative efforts between researchers and the healthcare services company Optum resulted in an 80% reduction in bias. However, without questioning the AI, prejudicial outcomes would have persisted against black individuals.
2. Representation of CEOs as predominantly male
Women constitute 27 percent of CEOs across the United States. However, a 2015 study revealed that only 11 percent of the individuals appearing in a Google image search for “CEO” were female. Shortly after, Anupam Datta conducted separate research at Carnegie Mellon University in Pittsburgh, discovering that Google’s online ad system frequently displayed high-paying job advertisements to men rather than women.
Google responded to this finding by noting that advertisers have the option to specify which demographics and websites should receive their ads. Gender is one such criterion that companies can set.
Though it has been suggested that Google’s algorithm might have autonomously concluded that men are more suited for executive roles, Datta and his team theorize that it might have reached this conclusion based on user behavior. For instance, if only men view and click on advertisements for high-paying positions, the algorithm learns to present those ads predominantly to men.
3. Amazon’s recruitment algorithm
Automation has been pivotal in Amazon’s dominance in e-commerce, whether in warehouses or in making pricing decisions. Some individuals who interacted with the company indicated that its experimental hiring tool utilized Artificial Intelligence to rate job applicants on a scale of one to five stars, similar to how customers evaluate products on Amazon. Once the company realized that its new system was not assessing candidates for technical roles in a gender-neutral way, predominantly favoring women, adjustments were made.
By analyzing resumes over a decade, Amazon’s algorithm could recognize patterns in candidates’ applications, most of which were male, reflecting the industry’s gender imbalance. Consequently, the algorithm learned to favor male applicants and penalized resumes that indicated a female identity. It also downgraded applications from those who graduated from two specific all-female institutions.
Amazon modified the program to be neutral regarding such keywords. However, this does not eliminate the potential for other biases to arise. Although recruiters considered the tool’s suggestions for hiring, they did not rely solely on those ratings. Ultimately, Amazon abandoned the initiative in 2017 after management lost confidence in the program.
How bias in AI mirrors societal biases
Regrettably, AI is not immune to human biases. While it can aid individuals in making fairer decisions, this is contingent on our commitment to ensuring equity in AI systems. Often, it is the data underpinning AI—not the methodology itself—that contributes to bias. Given this insight, here are several notable discoveries from a McKinsey analysis on addressing AI bias:
Models can be developed using data derived from human behavior or data reflecting social or historical inequalities. For instance, word embeddings, which are a set of techniques in Natural Language Processing, may showcase societal gender biases due to training on news articles.
Data collection methods or selection processes can introduce biases. An example is in criminal justice AI models, where oversampling certain areas could create an inflated representation of crime data, ultimately influencing policing.
Data created by users may perpetuate a cycle of bias. Research indicated that searches involving the term “arrest” appeared more frequently with names identifying as African-American compared to those identifying as white. Researchers speculated this trend occurs because users clicked on various versions related to their searches more often.
A Machine Learning system might uncover statistical correlations that are deemed socially unacceptable or illegal. For example, a model for mortgage lending might conclude that older individuals are more likely to default, subsequently lowering their credit scores. If this conclusion is drawn solely based on age, it could represent unlawful age discrimination.
Another relevant instance involves the Apple credit card. The Apple Card approved David Heinemeier Hansson’s application with a credit limit 20 times greater than that of his wife, Jamie Heinemeier Hansson. Additionally, Janet Hill, the spouse of Apple co-founder Steve Wozniak, received a credit limit that was only 10 percent of her husband’s. It is evident that evaluating creditworthiness based on gender is both improper and illegal.
What actions can we take to mitigate biases in AI?
Here are some suggested solutions:
Testing algorithms in real-world scenarios
Consider the case of job applicants. Your AI solution may be unreliable if the data used for training your machine learning model derives from a limited pool of job seekers. While this issue may not arise when applying AI to similar candidates, it becomes problematic when it is used for a group that was not included in the original dataset. In such a case, the algorithm may inadvertently apply learned biases to a set of individuals for whom those biases do not hold.
To avert this situation and identify potential problems, algorithms should be tested in environments that closely mimic their intended application in reality.
Acknowledging the concept of counterfactual fairness
Moreover, it’s essential to recognize that the concept of “fairness” and its measurement can be debated. This definition may also fluctuate due to external influences, necessitating that AI accounts for these variations.
Researchers have explored a wide range of strategies to ensure AI systems can meet these criteria, including pre-processing data, modifying choices post-factum, or embedding fairness criteria into the training process itself. “Counterfactual fairness” is one such approach, ensuring that a model’s decisions are consistent in a hypothetical scenario where sensitive attributes like race, gender, or sexual orientation have been altered.
Implementing Human-in-the-Loop systems
Human-in-the-Loop technology aims to achieve what neither a human nor a machine can do alone. When a machine encounters a problem it cannot resolve, human intervention is necessary to address the issue. This process generates a continuous feedback loop.
Through ongoing feedback, the system evolves and enhances its performance with each cycle. Consequently, Human-in-the-Loop systems yield more accurate results with sparse datasets and bolster safety and precision.
Transforming education pertaining to science and technology
In an article for the New York Times, Craig S. Smith suggests that a significant overhaul is required in how individuals are educated about tech and science. He posits that reforming science and technology education is essential. Currently, science is taught from a purely objective perspective. There is a need for more multidisciplinary collaboration and a rethinking of educational approaches.
He argues that certain matters require global consensus, while others should be handled on a local level. Similar to the FDA, there is a need for principles, standards, regulatory bodies, and public participation in decisions about algorithms’ verification. Merely collecting more diverse data will not resolve all issues; this is just one aspect.
Will these modifications address all issues?
Changes like these would be advantageous, but some challenges may necessitate more than just technological solutions and require a multidisciplinary perspective, incorporating insights from ethicists, social scientists, and other humanities scholars.
Furthermore, these modifications alone may not be sufficient in situations that involve assessing whether a system is fair enough to be deployed and determining if fully automated decision-making should be allowed in certain scenarios.
Will AI ever be free of bias?
The brief answer? Yes and no. While it is possible, the likelihood of achieving a completely impartial AI is slim. This is because it is improbable that an entirely unbiased human mind will ever exist. An AI system’s effectiveness is directly related to the quality of the input data it receives. If you can eliminate conscious and unconscious biases related to race, gender, and other ideological beliefs from your training dataset, you could create an AI system that makes impartial data-driven decisions.
However, in reality, this is doubtful. AI relies on the data it is provided and learns from. Humans generate the data used by AI. There are numerous human biases, and the ongoing identification of new biases continually expands the overall array of biases. As a consequence, the possibility of achieving a completely impartial human mind, as well as an AI system, seems unlikely. Ultimately, it is humans who produce the flawed data, and it is also humans and human-designed algorithms who check the data for biases and seek to correct them.
Nevertheless, we can address AI bias through data and algorithm testing and by implementing best practices for data collection, usage, and AI algorithm development.
In summary, as AI technology advances, it will increasingly influence the decisions we make. For instance, AI algorithms are utilized for medical information and policy decisions that significantly affect people’s lives. Therefore, it is crucial to investigate how biases can affect AI and what actions can be taken to mitigate this.
This article suggests several potential solutions, such as evaluating algorithms in real-world situations, considering counterfactual fairness, incorporating human oversight, and changing educational approaches concerning science and technology. However, these solutions may not fully resolve the issues of AI bias and might require a collaborative approach. The most effective way to counteract AI bias is to methodically assess data and algorithms while adhering to best practices in the collection, usage, and creation of AI algorithms.



{kind=link}